Introduction
There are many common methods for inputting and outputting spreadsheet data from Oracle. Below are two limited lists for talking purposes. You may well have others.
Our use case is to supplement the data in a user maintained spreadsheet using data from an Oracle database. We must as faithfully as possible maintain the existing data in the spreadsheet while adding new columns.
| app_read_xlsx_udt Use Case Diagram |
|---|
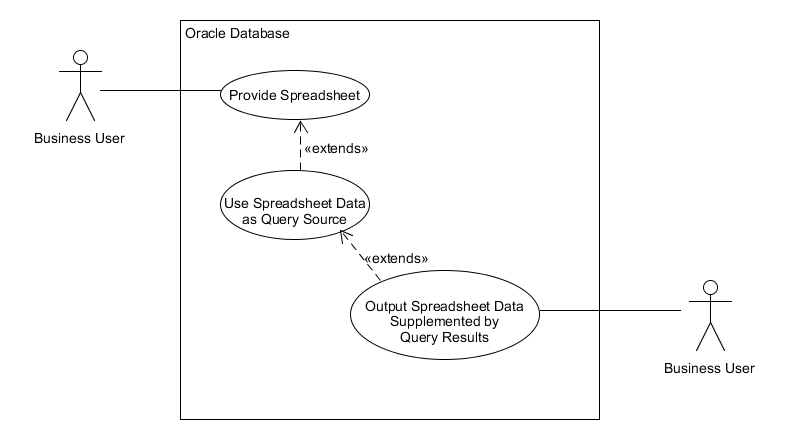 |
One limitation shared by common XLSX/Oracle methods is the concept that a column may contain only one datatype. A date column contains only dates or NULLs. A numeric column contains only numbers or NULLS. Yet, spreadsheet data cells may contain any kind of data and formatting can be specific to the cell. We traditionally think of columns in the spreadsheet of being a single datatype and formatting is typically accomplished at the column level, but our intrepid business user may place a string such as “Terminated” or “N/A” in a column that otherwise has Date values.
If we were tasked with replacing their entire business process, we would of course normalize this data and separate the non-date content into a separate column; however, our short term task is to supplement the data the business uses in an existing process. We do not control their process or their data.
How can we maintain the polymorphic cell content of the spreadsheet and replicate it on output?
Content
- Example Methods for Manipulating XLSX with Oracle
- Option Elimination
- ExcelGen and ANYDATA Columns
- app_read_xlsx
- Conclusion
Example Methods for Manipulating XLSX with Oracle
Input Spreadsheet to Oracle
- An ODBC connection from Excel to insert spreadsheet content into Oracle table - perhaps using a VB Macro
- Save as CSV and load with external table or sqlldr
- Toad, SQL Developer or other client tool to read xlsx and extract into an Oracle table
- An ETL tool like Informatica which can read XLSX
- A PL/SQL tool that can parse XLSX such as Anton Scheffer’s as_read_xlsx or Marc Bleron’s ExcelTable.
Output Spreadsheet from Oracle
- An ODBC connection from Excel to read a query resultset - perhaps using a VB Macro
- Output a CSV text file from Oracle and open with Excel
- Toad, SQL Developer or other client tool generate an XLSX file from a query resultset
- An ETL tool like Informatica which can generate XLSX
- A PL/SQL tool to generate XLSX directly in the database like Marc Bleron’s ExcelGen
- Python xlsxwriter
Option Elimination
A Microsoft Option
The most full featured option for this use case is the Microsoft Excel library available from Visual Basic or C#. One can create a macro directly inside the spreadsheet using an ODBC connection to the database to perform the task. Limitations are:
- The user’s personal Oracle login must have access to all needed queries and functions. Since the user’s personal login is not tracked as an IT asset, care must be taken to encapsulate all necessary access via appropriate roles. Even so, maintenance of user accounts and associating the correct roles to include access needed by this spreadsheet becomes a burden.
- The code lives on a User’s desktop or maybe a shared drive. Perhaps the gold copy could be kept under source code control and made available to the users, but it doesn’t really fit well with common SDLC practices. The business could also change the spreadsheet parts that are not related to the data pull. At that point it is out of sync with the IT maintained copy.
- When the user experiences problems, the first thing IT must question is whether the user is employing the latest version of the code.
- The expertise to perform this task, though not uncommon, is not necessarily in the toolbox for a journeyman Oracle developer.
An extension of this option may be to use a Sql Server database (or whatever it is called now) to host the operation on the spreadsheet. I have not done this and do not know limitations, but my understanding is these Excel libraries should be available to code that is run from the database. DBLink accounts that can connect to the Oracle database can be maintained for this server and the code can be put under source code control. This added complexity does not appeal to me, but a shop who already run Sql Server databases, especially those supporting batch operations and/or existing user interaction screens that include file transfer may favor this option.
Oracle Specific Options
As mentioned, most of the listed options stumble when faced with a column that can contain cells with different data types. We can reduce everything to text, but then when we output to a spreadsheet again, we’ve lost information and our business partner is not pleased. This eliminates using CSV or a client like Toad, SqlDeveloper or Informatica to deliver the data to the database.
We are left with as_read_xlsx or ExcelTable for the input, both of which can deliver the raw spreadsheet data at the cell level with data type intact.
Assuming we can maintain the polymorphic content information about individual cells on input, we face the same limitation on output. A tool like Toad, SQL Developer or Informatica reads resultsets from queries. I do not believe any of them have been enhanced to support the Oracle ANYDATA object type so we are restricted to cell data that is either character, date or number.
I mention Python xlsxwriter, but I really don’t know if it has such a capability. What I have seen of it in practice is that it takes a resultset from a query similarly to the others.
I set up this straw man with a non-exhaustive list of options, so there may well be another choice out there. I would love to hear about it if so. The choice I made is to use ExcelGen to create the output spreadsheet.
Of the two possible input tools, ExcelTable is more sophisticated and already supports providing the raw cell data as ANYDATA values. It has other functions that return ANYDATASET results which is fantastic, but these require you to provide the column type and header information in your code. I badly wanted to use the first row of the spreadsheet for the column headers and do not want to specify the data type. I considered adding functionality to do so, but was not encouraged. Perhaps I did not sell it well enough.
Although I wanted to use ExcelTable, the more I looked into it the bigger the sinking feeling I had that it was beyond a level of complexity I felt I could leave with my employer. Without community support it was not an option.
By process of elimination we are left with as_read_xlsx which is a perfectly serviceable tool that is in widespread use.
ExcelGen and ANYDATA Columns
The currently published version of ExcelGen does not support ANYDATA data type input columns. I created a fork and Pull Request adding this functionality, but was not aware that Marc was in the midst of a refactor/redesign of ExcelGen and he politely declined the PR. He agreed that allowing ANYDATA input columns was useful and he liked the idea of supporting it. I’ll call that a soft commitment. If the next version of ExcelGen does not support ANYDATA input, I’ll create another pull request to add it. I’m fairly confident it will be included in a future release one way or another.
Meanwhile, to implement the solution discussed here you will need to use my forked version of ExcelGen.
app_read_xlsx
Although it uses as_read_xlsx as the underlying workhorse, app_read_xlsx takes care of many of the details needed to treat a spreadsheet as a row source, using the first row data values as the column names and output column headers.
The documentation found in the README.md at the above link discusses some of what is covered in this article. It also contains what I think is a decent example showing the problem and the solution. I am not going to repeat those here but am going to borrow the How it Works section from that document.
Overview
- The input datastream from as_read_xlsx is a table of cell data. The ordinal row and column numbers of the spreadsheet are columns/attributes in this data stream.
- Empty cells are not present in the data.
- The concept of column headers and database identifiers for the columns is not present in this structure.
- Each cell is represented with a polymorphic structure containing a cell_type attribute and a value in one of the attributes string_val, number_val, date_val, formula. formula is out of scope for this implementation. Our design pattern converts this polymorphic structure into an Oracle ANYDATA object type.
Presenting the cell data in a two dimensional standard database pattern requires
- extract column identifiers and number of columns from the first row of the input data
- pivot spreadsheet columns into rows
- densify the missing/empty cells
- convert multi-attribute polymorphic cell representation into ANYDATA objects
- present the ANYDATA cell objects in standard database TABLE structure with rows and columns named from the spreadsheet column headers
Doing this requires a runtime determination of the resultset type. It is not difficult to do this for a PL/SQL cursor as we can use a weakly typed SYS_REFCURSOR. It is much harder to present the results to the SQL engine in a way that the resultset may be joined and extended.
Considerations
When one hears the term polymorphic resultset, we instantly turn to the cool new Oracle toy (well, new as of Oracle 18c) of Polymorphic Table Functions. Unfortunately, this design pattern only supports standard Oracle datatypes. Object types such as ANYDATA are not supported, at least as of Oracle 19c.
Another method for achieving this is the ANYDATASET technique which is built with ANYTYPE. Building these requires producing ODCI level code, whether in PL/SQL or another compiled language such as Java or C. Although this pattern can be followed reasonably well at a cookbook level for standard data types with a moderate level of study, extending it to handle piece-wise construction of complex object types such as the ANYDATA objects is non-trivial. (see ExcelTable.getRows in ExcelTable for an example of using ANYDATASET with standard datatypes.) This is a level of complexity the author has seldom observed within most corporate IT departments. If there were community support of this I would be willing, but for this project it exceeds the complexity level with which I’m comfortable encumbering my current employer.
The level of complexity I settled on was using a compile time known object type representing a row, and standard pipelined table function returning a collection of that row object type. This is a well known and documented technique that should be in the wheelhouse of most journeyman level Oracle practitioners. The only slightly tricky part I added was the use of a nested table collection inside this object and an object method named get for extracting members of that nested table in a SQL statement.
Technique
We start with a collection object type of ANYDATA objects.
CREATE OR REPLACE TYPE arr_anydata_udt FORCE AS TABLE OF sys.anydata;
/
Next we build an object type that can be piped from our table function:
CREATE OR REPLACE TYPE app_read_xlsx_row_udt FORCE AS OBJECT (
data_row_nr NUMBER
,aa arr_anydata_udt
,MEMBER FUNCTION get(p_i NUMBER) RETURN SYS.anydata
);
/
CREATE OR REPLACE TYPE BODY app_read_xlsx_row_udt AS
MEMBER FUNCTION get(p_i NUMBER)
RETURN SYS.anydata
AS
BEGIN
RETURN aa(p_i);
END get;
END;
/
The get method is necessary to access a member of the nested table collection from within SQL (inside PL/SQL you could just use aa(i)).
Then to be able to define our pipelined table function we need a nested table type of these elements:
CREATE OR REPLACE TYPE arr_app_read_xlsx_row_udt FORCE AS TABLE OF app_read_xlsx_row_udt;
/
Our pipelined table function (which is a static method of our main object type app_read_xlsx_udt) can then be declared as:
STATIC FUNCTION get_data_rows(
p_ctx NUMBER
,p_col_cnt NUMBER
) RETURN arr_app_read_xlsx_row_udt PIPELINED
This still leaves the task of generating a SQL select list that turns the collection elements aa.get(i) into columns with an identifier based on the first row of the spreadsheet. That is done by calling the get_sql method of app_read_xlsx_udt. It builds a dynamic SQL statement for you that you can then use as part of a larger application level SQL statement as shown in the examples section and reproduced here.
SELECT X.R.data_row_nr AS data_row_nr,
X.R.get(1) AS "id"
,X.R.get(2) AS "data"
,X.R.get(3) AS "ddata"
FROM (
SELECT VALUE(t) AS R -- full object, not the object members * would provide
FROM TABLE(LEE.app_read_xlsx_udt.get_data_rows(1,3)) t
) X
Code Dive
The manual page for app_read_xlsx_udt constructor describes how the output from as_read_xlsx is read into a global temporary table (GTT). Subsequent reads of this data for the first row determine the number of columns and column headers to populate the object attributes during the constructor call. After that we read the row data from the GTT using the static pipelined table function app_read_xlsx_udt.get_data_rows.
This code is a little interesting in how it uses a restricted package ( ACCESSIBLE BY (app_read_xlsx_udt) ) to maintain a set of session specific context numbers allowing for multiple spreadsheets to be read simultaneously in a single session. The package also implements the call to as_read_xlsx when it populates the GTT. You can look at your leisure.
In Overview we listed the tasks the function needed to perform in a bullet list. Most of these tasks are handled in the static pipelined table function app_read_xlsx_udt.get_data_rows via a cursor that uses a bind variable for the number of columns we have in our input (gathered during object constructor call).
These two bullet items are covered by the first code section:
- densify the missing/empty cells
- convert multi-attribute polymorphic cell representation into ANYDATA objects
First, generate a Common Table Expression (CTE or WITH Clause view) consisting of an integer for each column.
CURSOR c_filled_gaps IS
WITH cols AS (
SELECT level AS col_nr FROM dual CONNECT BY level <= p_col_cnt
)
Next, grab our data from the GTT, but only the rows and columns of interest.
, this_ctx_cols AS (
SELECT row_nr, col_nr, cell_type, string_val, date_val, number_val
FROM as_read_xlsx_gtt
WHERE ctx = p_ctx AND row_nr > 1 AND col_nr <= p_col_cnt
)
The CASE statement below examines the data type of the cell and calls the appropriate static constructor for an ANYDATA object. Notice the funky method for creating a NULL ANYDATA object. If you find a less kludgey method, let me know.
The PARTITION BY and RIGHT OUTER JOIN are an Oracle technique I do not know the name of for densifying data. Heck, that could be the official name of the technique. It makes sure that on any given row_nr we selected from the GTT, there will be a row in the output for every column.
, ad_cols AS (
SELECT t.row_nr, cols.col_nr
,CASE t.cell_type
WHEN 'S' THEN SYS.ANYDATA.convertVarchar2(t.string_val)
WHEN 'D' THEN SYS.ANYDATA.convertDate(t.date_val)
WHEN 'N' THEN SYS.ANYDATA.convertNumber(t.number_val)
ELSE SYS.ANYDATA.convertVarchar2(NULL) -- must have a placeholder for collect
END AS ad
FROM this_ctx_cols t
PARTITION BY (t.row_nr) -- fill gaps for empty cells
RIGHT OUTER JOIN cols
ON cols.col_nr = t.col_nr
)
Now that we are promised a row for every cell, we can use a COLLECT aggregation function to build a nested table collection object in SQL. That takes care of pivoting the column data into a single row per spreadsheet row, if not exactly pivoting into columns yet.
- pivot spreadsheet columns into rows
To complete the cursor query we plug these values into the default constructor for our app_read_xlsx_row_udt object described earlier. That is what our function must PIPE ROW out.
, ad_arr AS (
SELECT row_nr - 1 AS data_row_nr
,CAST( COLLECT(ad ORDER BY col_nr) AS arr_anydata_udt) AS vaa
FROM ad_cols
GROUP BY row_nr
)
SELECT app_read_xlsx_row_udt(data_row_nr, vaa)
FROM ad_arr
;
The rest of the function is simple boilerplate for a pipelined table function:
OPEN c_filled_gaps;
LOOP
FETCH c_filled_gaps BULK COLLECT INTO v_arr LIMIT 100;
EXIT WHEN v_arr.COUNT = 0;
FOR i IN 1..v_arr.COUNT
LOOP
PIPE ROW(v_arr(i));
END LOOP;
END LOOP;
CLOSE c_filled_gaps;
RETURN;
No matter how many columns we have or what our column names are, we have a single compile-time representation of our resultset coming from this pipelined table function. With a little help from member function app_read_xlsx_udt.get_sql we can get our columns out with proper names using regular SQL and use it as if it had come from a table.
You can look at the code for get_sql at your leisure, but the example shown in the Technique section and repeated next is the best way to understand it:
SELECT X.R.data_row_nr AS data_row_nr,
X.R.get(1) AS "id"
,X.R.get(2) AS "data"
,X.R.get(3) AS "ddata"
FROM (
SELECT VALUE(t) AS R -- full object, not the object members * would provide
FROM TABLE(LEE.app_read_xlsx_udt.get_data_rows(1,3)) t
) X
I’ll mention something that confounds those who have not used Oracle objects often. In order to access a member method or element of an object you must use a table alias as part of the name. One cannot rely on an actual table name or an implied (no) table name; it must be a table alias. In this case the table alias is ‘X’.
The other thing to mention is the use of the VALUE function. The most common way we extract data from a pipelined table function is via SELECT *. If we do that here, we will get the elements of the app_read_xlsx_row_udt object rather than the object itself. We need the get member method of the object, so it is important that we retrieve the object intact rather than the object elements. VALUE gives us the actual object returned from the pipelined table function rather than the object elements. It’s relatively obscure.
Conclusion
This turned out to be a much harder problem than I thought it would be when I started. Limitations of Polymorphic Table Functions and the complexity of ANYTYPE/ANYDATASET took me off guard. It would have been easiest to craft one-off solutions for each spreadsheet by writing a custom cursor, but it felt like the wrong answer. Creating app_read_xlsx was the result. It is a bit messier than I would like in the way it gives you a SQL statement for your program to incorporate, but I feel it is an appropriate level of abstraction given the requirements and limitations.
Hope you find both the tool and the journey to get here helpful.