Introduction
How can we store a generic two dimensional table in PL/SQL, bind it to SQL as a data source and generate a cursor from it? We have a variable number of columns, so a Record Type is not practical. We’ll explore some options.
A Well Defined Problem
We have a table with known number of columns and column names. We want to create a structure that represents spreadsheet column headers for a report that reads from this table. I better repeat that. We are not discussing a structure for holding the data from the table. We want a similar structure to hold multiple rows of column header information for a spreadsheet.
Here is an image of the spreadsheet we will produce.
| Figure 1 - Multi-Row Spreadsheet Headers Try 1 |
|---|
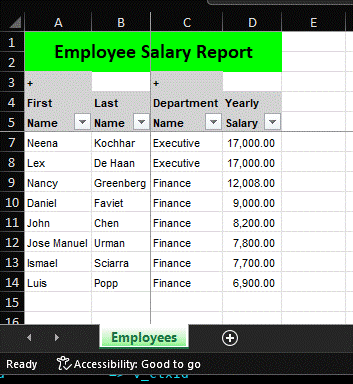 |
Rows 3, 4 and 5 are our column header rows. The columns are from the hr.employees and hr.departments tables. The tool we use to generate the spreadsheet requires that we provide a SYS_REFCURSOR or a SQL query string as an input parameter. We’ll work with a SYS_REFCURSOR here to include bind variables.
We could generate a SQL query string as:
OPEN v_sys_refcursor FOR
q'{SELECT '+', NULL, '+', NULL FROM dual
UNION ALL
SELECT 'First', 'Last', 'Department', 'Yearly' FROM dual
UNION ALL
SELECT 'Name', 'Name', 'Name', 'Salary' FROM dual}'
;
I’m less than impressed. We could create a pair of public types in our package (declared in the package specification so that the SQL engine can see it):
TYPE t_header_rec IS RECORD(
first_name VARCHAR2(32)
,last_name VARCHAR2(32)
,department_name VARCHAR2(32)
,yearly_salary VARCHAR2(32)
);
TYPE t_arr_header_rec IS TABLE OF t_header_rec;
Then we can assign the data to it like so in our procedure declaration:
v_arr_headers t_arr_header_rec := t_arr_header_rec(
t_header_rec('+',NULL,'+',NULL)
,t_header_rec('First','Last','Department','Yearly')
,t_header_rec('Name','Name','Name','Salary')
);
And open a cursor that reads from it:
OPEN v_sysrefcursor FOR q'{SELECT
first_name, last_name, department_name, yearly_salary
FROM TABLE(:header_table)}'
USING v_arr_headers
;
There is no ORDER BY here. We are depending on the implementation to provide the rows in the same order as the collection. It seems a pretty safe bet, but I have searched long and hard for documentation that makes a promise on this. Oracle pulled the rug out from under us once before when we were dependent on the implementation of GROUP BY via a sort. Tom Kyte wrote adamantly that the only way you can guarantee the order of records is to use an ORDER BY clause. Yet I cannot think of a reason why the current implementation providing the records in the same order as the collection would change.
A Generic Solution
I want to refactor my larger problem of providing a data structure containing the header row content for any spreadsheet, not just this one report. We will not have a Record Type with a fixed number of columns. For each row we need a nested table of strings. We’ll define a schema level collection Object:
CREATE OR REPLACE TYPE arr_varchar2_udt AS TABLE OF VARCHAR2(4000);
/
You probably already have one of those available to you in your own schema or perhaps a common schema. Oracle ships with several of them.
We also need a nested table of those puppies to build our two dimensional structure in our PL/SQL program:
CREATE OR REPLACE TYPE arr_arr_varchar2_udt AS TABLE OF arr_varchar2_udt;
/
Now our procedure declaration becomes:
v_arr_headers arr_arr_varchar2_udt := arr_arr_varchar2_udt(
arr_varchar2_udt('+',NULL,'+',NULL)
,arr_varchar2_udt('First','Last','Department','Yearly')
,arr_varchar2_udt('Name','Name','Name','Salary')
);
There is a glitch in the matrix though. How do we extract the individual elements of each row in the SQL statement for the cursor? Here is one way.
Note the careful use of table aliases. Object access in SQL has a quirk where an alias for the table or Common Table Expression (CTE) name is required.
One triksie part here is the join in the CTE named b. We are joining to a column in our rowset from CTE named a. Think that through. For each row from a, we treat the column in that row like it is a table. When we join to it we are essentially unpivoting that column into multiple rows, one for each value in the array named col. CTE c has a separate record for every column on every line of our headers. We rank them in the order they came out of the collection so we can pivot them in the final select.
-- v_sql declared as a CLOB
v_sql := q'{WITH a AS (
SELECT rownum AS rn, t.COLUMN_VALUE AS rec -- rec is a nested table arr_varchar2_udt
FROM TABLE(:header_table) t
)
, b AS (
SELECT rn, rownum AS crn, c.COLUMN_VALUE AS col
FROM a t
INNER JOIN TABLE(t.rec) c
ON 1=1
)
, c AS ( -- could I have done math with rn and crn instead? not easily.
SELECT rn, ROW_NUMBER() OVER (PARTITION BY rn ORDER BY crn) AS cn, col
FROM b
) SELECT }';
-- create a pivot aggregate for each column
DECLARE
l_comma VARCHAR2(1);
BEGIN
FOR i IN 1..v_arr_headers(1).COUNT
LOOP
v_sql := v_sql||l_comma||q'{
MAX(CASE WHEN cn = }'||TO_CHAR(i)||' THEN col END) AS c'||TO_CHAR(i);
l_comma := ',';
END LOOP;
END;
v_sql := v_sql||q'{
FROM c
GROUP BY rn
ORDER BY rn}';
OPEN v_sysrefcursor FOR v_sql USING v_arr_headers;
Once again we are depending on Oracle to provide the rows in the same order as the collection. I’m hoping I’m retired before that changes. Yeah, yeah, you think I’m worried about a boogeyman that will never pop out from under the bed. Told ya, I’ve seen it before.
With some formatting to make it easier to see the output, here is what I ran in sqlplus for a test:
set pagesize 0
set trimspool on
set linesize 100
column c1 format a24
column c2 format a24
column c3 format a24
column c4 format a24
var curs REFCURSOR
DECLARE
v_arr_headers arr_arr_varchar2_udt := arr_arr_varchar2_udt(
arr_varchar2_udt('+',NULL,'+',NULL)
,arr_varchar2_udt('First','Last','Department','Yearly')
,arr_varchar2_udt('Name','Name','Name','Salary')
);
v_sql CLOB;
--v_sysrefcursor SYS_REFCURSOR;
BEGIN
v_sql := q'{WITH a AS (
SELECT rownum AS rn, t.COLUMN_VALUE AS rec -- rec is a nested table arr_varchar2_udt
FROM TABLE(:header_table) t
)
, b AS (
SELECT rn, rownum AS crn, c.COLUMN_VALUE AS col
FROM a t
INNER JOIN TABLE(t.rec) c
ON 1=1
)
, c AS ( -- could I have done math with rn and crn instead? not easily.
SELECT rn, ROW_NUMBER() OVER (PARTITION BY rn ORDER BY crn) AS cn, col
FROM b
) SELECT }';
-- create a pivot aggregate for each column
DECLARE
l_comma VARCHAR2(1);
BEGIN
FOR i IN 1..v_arr_headers(1).COUNT
LOOP
v_sql := v_sql||l_comma||q'{
MAX(CASE WHEN cn = }'||TO_CHAR(i)||' THEN col END) AS c'||TO_CHAR(i);
l_comma := ',';
END LOOP;
END;
v_sql := v_sql||q'{
FROM c
GROUP BY rn
ORDER BY rn}';
OPEN :curs FOR v_sql USING v_arr_headers;
END;
/
print curs
And the output:
SQL> @x.sql
PL/SQL procedure successfully completed.
+ +
First Last Department Yearly
Name Name Name Salary
SQL>
It works. It’s ugly. Can we make it better?
Refactor Using a WITH Clause PL/SQL Function
In PL/SQL we can get the value of a collection element with the syntax v_arr(i) where i is the index value. There is no equivalent syntax in SQL. That is why we had to do the self-join in the example above.
Rather than self-joining to our collection of columns to break them into separate rows, then pivoting them back into columns afterwards, let’s give ourselves a Function that we can call in SQL to do it. We could define the function in a package or standalone, but as of Oracle 12.1 we can do it in-line with our SQL.
I like this much better than the convolutions above:
set pagesize 0
set trimspool on
set linesize 100
column c1 format a24
column c2 format a24
column c3 format a24
column c4 format a24
var curs REFCURSOR
DECLARE
v_arr_headers arr_arr_varchar2_udt := arr_arr_varchar2_udt(
arr_varchar2_udt('+',NULL,'+',NULL)
,arr_varchar2_udt('First','Last','Department','Yearly')
,arr_varchar2_udt('Name','Name','Name','Salary')
);
v_sql CLOB;
--v_sysrefcursor SYS_REFCURSOR;
BEGIN
v_sql := q'{WITH
FUNCTION wget(
p_arr ARR_VARCHAR2_UDT
,p_i NUMBER
) RETURN VARCHAR2
AS
BEGIN
RETURN p_arr(p_i);
END;
a AS (
SELECT rownum AS rn, t.COLUMN_VALUE AS arr
FROM TABLE(:header_table) t
)
SELECT wget(a.arr,1) AS c1}';
FOR i IN 2..v_arr_headers(1).COUNT
LOOP
v_sql := v_sql||', wget(a.arr,'||TO_CHAR(i)||') AS c'||TO_CHAR(i);
END LOOP;
v_sql := v_sql||q'{
FROM a
ORDER BY rn}';
OPEN :curs FOR v_sql USING v_arr_headers;
END;
/
print curs
And the output:
SQL> @y.sql
PL/SQL procedure successfully completed.
+ +
First Last Department Yearly
Name Name Name Salary
SQL>
That looks pretty good. We could use it as-is for any project and be pretty pleased.
Refactoring the Refactoring
I like this concept of opening a cursor from a two dimensional collection object enough that I added a function named get_cursor_from_collections to my PL/SQL utility package named app_csv_pkg. You can find this at on github at plsql_utilities. There is a version of get_cursor_from_collections in the package perlish_util_pkg too if you are bent that way.
Also in app_csv_pkg is a function that will parse a CLOB containing CSV data (like our column headers) and return an arr_arr_varchar2_udt object. How handy is that? Let’s see.
set pagesize 0
set trimspool on
set linesize 100
column c1 format a24
column c2 format a24
column c3 format a24
column c4 format a24
var curs REFCURSOR
DECLARE
/*
v_arr_headers arr_arr_varchar2_udt := arr_arr_varchar2_udt(
arr_varchar2_udt('+',NULL,'+',NULL)
,arr_varchar2_udt('First','Last','Department','Yearly')
,arr_varchar2_udt('Name','Name','Name','Salary')
);
*/
v_arr_headers arr_arr_varchar2_udt := app_csv_pkg.split_clob_to_fields(
q'{+,,+,
First,Last,Department,Yearly
Name,Name,Name,Salary}'
);
--v_src SYS_REFCURSOR;
BEGIN
--v_src := app_csv_pkg.get_cursor_from_collections(v_arr_headers);
:curs := app_csv_pkg.get_cursor_from_collections(v_arr_headers);
END;
/
print curs
And the output:
PL/SQL procedure successfully completed.
+ +
First Last Department Yearly
Name Name Name Salary
SQL>
Now we’re cooking with gas!
You may already have the column headers in a spreadsheet. I often have them as part of a requirements document. Export them as CSV (Save As CSV might give you an evil windows character at the start of the file - use Export instead). Now you can copy/paste that file content directly into your PL/SQL program. It will even handle commas embedded in the fields correctly.
Conclusion
This seemed like a problem that should not be so hard in PL/SQL, but it wasn’t as easy as one would like. I like where this wound up with some utility methods to make it easier.