Introduction
A batch technique I often encounter creates staging tables for intermediate results, then breaks a problem down into multiple smaller steps, each one populating (and sometimes updating!) staging tables before consolidating into a final result. The argument is that breaking down the problem into smaller, more easily understood steps is a good programming practice, which on its face is true. There is also an advantage in being able to inspect the intermediate results while doing development and QA (and perhaps in production support).
| Small Steps Using Staging Tables |
|---|
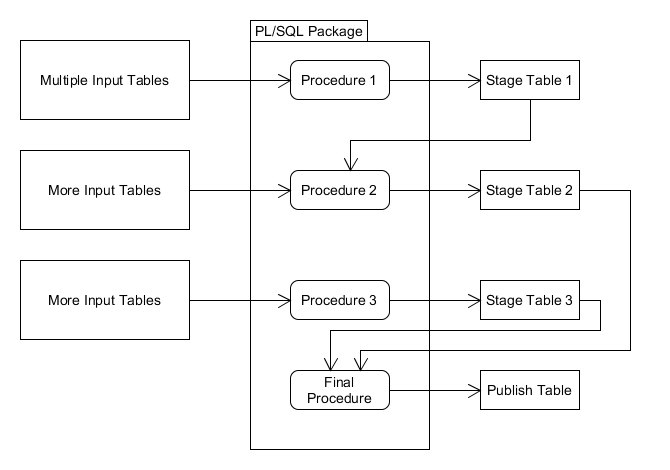 |
Assuming the developer’s code is optimized as well as the Oracle optimizer would if given the entire problem, the only extra cost is the instantiation of intermediate results. Generally, I have not found the assumption to be true, but let’s give practitioners of this pattern the benefit of the doubt. Most of the time one can achieve reasonable performance using this technique.
Yet the overhead in undo/redo logging for these staging tables is not free. The total run-time will be longer using this technique, sometimes substantially. The DBA is probably gathering statistics in a job that will process your staging tables needlessly. In addition, we are bloating the undo and redo logs, plus these tables get backed up and take up room on “disk”.
If you would like a refresher course on undo and redo, my personal favorite is from Tom Kyte’s book Expert Oracle Architecture.
For our purposes just know those staging tables are not free, even if you use direct path load.
Furthermore, practitioners often employ UPDATEs and DELETEs which are much more expensive in Oracle than INSERTs. If you can gather the information you need while doing the INSERT, it is difficult to justify doing so after the fact with an UPDATE even to simplify your understanding of the solution. If you find yourself adding indexes to your staging table to facilitate subsequent operations, you might want to rethink your approach. (Of course, there are exceptions where the cost of creating an index on a staging table and using it to perform updates/deletes is the best answer, but it is extremely rare.)
Using WITH Subquery Factoring Alternative
Multiple Small Steps
We can write the same task in a single SQL statement using the WITH syntax to create multiple sequential views, aka Common Table Expressions (CTE). This retains the advantage of breaking the problem into multiple smaller steps while not paying the undo/redo cost of the staging tables. Instead, the execution plan allows the database engine to merrily pipeline results from join to join without ever writing out the intermediate resultsets. (Well, technically it can buffer intermediate resultsets in the temp tablespace between operations, and some of that may write to disk if there is not enough memory, but from a logical standpoint nothing is written to the database).
Not only that, but the optimizer can merge the views into the main query when it finds a better plan than the one you envisioned when you designed the program and broke it down into parts. Letting Oracle do the entire set of work in a single statement is almost always the most efficient and fastest solution.
From the developer’s point of view, we have broken down the problem into smaller, understandable chunks as CTE’s. It is the Oracle optimizer that is taking on the complexity, not the developer. Granted, your explain plan is going to be bigger and take some effort to relate to your code, but it should be in the wheelhouse for any serious Oracle practitioner to understand what the Optimizer does with your query.
Intermediate Resultsets
As for being able to see intermediate resultsets, at least during development and performance testing you can easily alter the query to stop after any given CTE, then select from that CTE. You can select the entire resultset or use a where clause or even analytic. For example:
WITH step1 AS (
...
), step2 AS (
...
), step3 AS (
...
) SELECT *
FROM step 3
INNER JOIN step2
ON ...
You make a copy and interject your debug select like so:
WITH step1 AS (
...
), step2 AS (
...
) select mycollist from step2 where xyz = ‘mykey’;
– remainder of quuery does not run
), step3 AS (
...
) SELECT *
FROM step 3
INNER JOIN step2
ON ...
It can also be helpful to do this if you want to look at the Explain Plan for the smaller subset of the query.
When you want to resume going through the query and looking at parts, you can put dash-dash in front of that line and continue going down the query testing each part. That way you can come back to it for further analysis.
CTE Used Multiple Times
If you use a CTE within the full query more than once, then Oracle must instantiate it. This will appear as Temp Table Transformation with a Load As Select below it near the start of the Explain Plan. For all practical purposes this is the same as populating a global temporary table. It uses the default temporary tablespace. As far as I can tell, this is effectively a direct path load of the transient global temporary table that does not generate much undo (and by default creating undo also generates redo for that undo). This addresses another stated purpose for using staging tables – to be able to use them more than once.
In this scenario when you have a large resultset, it is still going to be almost as expensive to instantiate it in Temporary space as it would be to do a direct path load into a staging table (except for the redo logging). The only way around that is to figure out how to avoid reusing the CTE. You may surprise yourself and find that you can.
Cardinality and Statistics
Using WITH/CTE technique rather than staging tables, the optimizer has an advantage of knowing how each intermediate result was gathered. It can estimate the cardinality. When using staging tables, you must either gather statistics on the staging table or provide a cardinality hint to the using query. Gathering statistics can be even more expensive than the redo logging.
Discoveries from Refactoring Staging Tables to a Single SQL
NO_MERGE Hint
The optimizer will sometime merge subqueries together that you can prove via experimentation is a bad idea. Purists will tell you that you just don’t have your statistics right. I don’t argue. I just hint the damn thing.
For the example below, Oracle will almost always merge the view named keys into the main select and do a single HASH UNIQUE.
WITH keys AS (
SELECT DISTINCT key1, key2, key3
FROM key_source
) SELECT DISTINCT resultfieldlist
FROM keys k
INNER JOIN sourcetable s
ON s.key1 = k.key1 AND s.key2 = k.key2 AND s.key3 = k.key3
I can prove that in case of the query I was tuning, we are better off gathering a DISTINCT set of keys before joining to sourcetable. The optimizer flat out refuses and merges the “set of keys” view into the join query so that it only has to do a single HASH UNIQUE after the join. Yet the duplication of the keys between those two sources is multiplicative. If we let Oracle have its way, the result set going into the single HASH UNIQUE the optimizer is so proud of is ginormous. I know from trial and error for this particular set of inputs, we are better off with two separate HASH UNIQUE operations.
In this scenario you can force Oracle to do two separate HASH UNIQUE operations by using the NO_MERGE hint:
WITH keys AS (
SELECT /*+ NO_MERGE */ DISTINCT
key1, key2, key3
FROM key_source
) SELECT DISTINCT resultfieldlist
FROM keys k
INNER JOIN sourcetable s
ON s.key1 = k.key1 AND s.key2 = k.key2 AND s.key3 = k.key3
I’ve also seen cases where Oracle chooses to merge in a subquery containing an analytic, doing the join first and then the analytic and the filter using the analytic column that was supposed to be applied before doing the join.
WITH keys AS (
SELECT ...
,ROW_NUMBER() OVER (PARTITION BY xyz ORDER by last_modified_dt DESC) AS rn
FROM key_source
) SELECT resultfieldlist
FROM keys k
INNER JOIN sourcetable s
ON s.key1 = k.key1 AND s.key2 = k.key2 AND s.key3 = k.key3
WHERE k.rn = 1
The optimizer has determined that it can reduce the resultset better by doing the join first, shrinking the number of rows from key_source, then doing the analytic sort and filter. Maybe the optimizer is right. When it is wrong, you will notice a humongous hash join taking forever in order to save a little bit on that sort. That is when you can try making it do the sort first using NO_MERGE:
WITH keys AS (
SELECT /*+ NO_MERGE */ ...
,ROW_NUMBER() OVER (PARTITION BY xyz ORDER by last_modified_dt DESC) AS rn
FROM key_source
) SELECT resultfieldlist
FROM keys k
INNER JOIN sourcetable s
ON s.key1 = k.key1 AND s.key2 = k.key2 AND s.key3 = k.key3
WHERE k.rn = 1
I do not advise reaching for the NO_MERGE hint until you suspect a problem, and even then you should try it both ways. Need for the hint in these scenarios is the exception, as most of the time the optimizer is right. Yet the optimizer relies on rules of thumb and guesses that do not necessarily match your data. Even with good statistics with histograms available, much of the optimizer logic is based on probabilities and rules of thumb. It is not always right. Figuring out how to give the optimizer enough information to come up with the right answer, as one school of purists advocate, is not practical.
Fat Resultset and Big Joins
When we get into very large joins when one or both of the input datasets are very fat (lots of columns/big fat records), there is a technique from the staging table school of thought you might want to employ. The technique is to grab only the join keys from one of your sources (likely your target record that you are joining additional fields into) and use those keys to gather the data from the other table, then once you have the values you need, join them back into the main query.
Why do the join twice? Consider that the table you are reading is very large with many more rows than the one you are joining into. The proper way to do this is hash the one with less rows and probe it from the new table; yet, because it is so fat, hashing the entire thing overflows our available PGA memory pushing us off into a onepass or multipass hash join. In this scenario we could be better off just hashing the distinct set of join keys while we probe it from the large source table until we have only the data we need.
Eventually we still have to join to our big fat target resultset, but now we have a smaller footprint of data to do it with. We can reverse which resultset is hashed to the one that fits in memory.
I still am likely to use WITH subqueries to do it but have at times found a separate staging table is a faster answer. I have not completely grasped the reason, but suspect it revolves around the PGA size and the amount of memory paged to disk for our reuse of our main resultset.
Sometimes an Update Really is Faster
We have a very large and fat resultest, and need to update values in a very small number of rows. We need to make a full table scan pass through our data to select candidate rows (or the keys from candidate rows) and join them to our source. We cannot avoid that first full scan. If we have a staging table, we can bring the ROWID along, then use that for the MERGE ON clause join back into the staging table.
MERGE INTO staging_table t
USING (
WITH lkup_value AS (
SELECT s.rowid AS s_rowid, lk.update_value
ROW_NUMBER() OVER (PARTITION BY s.key1, s.key2 ORDER BY lk.effective_date DESC) AS rn
FROM staging_table s
INNER JOIN lookup_table lk
ON lk.key1 = s.key1 AND lk.key2 = s.key2...
AND s.create_dt >= lk.effective_date
) SELECT s_rowid, update_value
FROM lkup_value
WHERE rn = 1
) q
ON (t.rowid = q.s_rowid)
WHEN MATCHED THEN UPDATE SET
update_value = q.update_value
Consider how we would do this in a series of steps using WITH clause CTEs in a single INSERT without the staging table:
INSERT INTO staging_table
WITH x AS (
...
), lkup_value_1 AS (
SELECT x.key1, x.key2, lk.update_value
ROW_NUMBER() OVER (PARTITION BY x.key1, x.key2 ORDER BY lk.effective_date DESC) AS rn
FROM x
INNER JOIN lookup_table lk
ON lk.key1 = x.key1 AND lk.key2 = x.key2...
AND x.create_dt >= lk.effective_date
), lkup_value AS (
SELECT key1, key2, update_value
FROM lkup_value_1
WHERE rn = 1
), y AS (
SELECT x.field1, x.field2...
,CASE WHEN lk.key1 IS NOT NULL THEN lk.update_value ELSE x.update_value END AS update_value
FROM x
LEFT OUTER JOIN lkup_value lk
ON lk.key1 = x.key1 AND lk.key2 = x.key2
)...
Even though we are only changing a few rows with clause ‘y’, we must run all of the rows from ‘x’ through this join with lkup_value clause. I have observed situations where keeping a staging table and doing the MERGE as shown above is superior to doing everything in a single query. This surprised me. I started the task with the expectation that I could eliminate all of the staging tables. It was not the answer I wanted, but it was the answer I found.
Conclusion
To break a database problem into small, understandable chunks you can use the WITH clause Common Table Expressions (CTE) instead of staging tables. There are more benefits than downside to this technique, but there are some exceptional circumstances where using intermediate staging tables is the best approach. Understand how the optimizer processes what you have designed as sequential steps (most of which are pipelined), and use hints when absolutely necessary to guide the optimizer away from suboptimal plans. A detailed understanding of the memory involved with HASH joins can help you design non-obvious solutions for very large dataset operations.