Why Polymorphic Table Functions (PTF)?
They let you code a resultset transformation for the SQL engine without knowing at compile time either or both of
- The input cursor/resultset definition.
- The output cursor/resultset definition.
Ordinary Pipelined Table Functions already let you consume any type of input, but you must build your own code to figure out what is in it, generally by using DBMS_SQL. If you want to see how that is done, I have a User Defined Type Object app_dbms_sql_udt you can check out. Ordinary Pipelined Table Functions require that you define the output type at compile time.
Even if you can define your output resultset at compile time, the PTF functionality takes care of many of the details you must otherwise encode manually with DBMS_SQL. As I’ll demonstrate later, the amount of code needed to produce a CSV file generator is substantially less using a PTF than DBMS_SQL.
Polymorphic Table Function Tutorials and Examples
Oracle’s introduction to Polymorphic Table Functions is in the Database PL/SQL Language Reference 12.6 Overview of Polymorphic Table Functions. PL/SQL Packages and Types Reference has documentation for the DBMS_TF package that provides the server side implementation. When I want to really understand the types and constants I found it easier to look directly at the DBMS_TF package specification in the database using the Toad or SqlDeveloper schema browser. The types and constants are scattered through the documentation which makes them a little harder to put together than looking straight at the package spec.
The best beginner introduction to PTFs I found was by Tim Hall Polymorphic Table Functions in Oracle Database 18c. He has simple examples to lead you in gently.
There are a suite of example PTF implementations in the Oracle LiveSql collection. Enter the search term “polymorphic table function”. This article from Oracle Magazine by Chris Saxon goes along with one of them and I found it helpful.
Replication_Factor
The general design pattern for a PTF is that it transforms rows from one result set into another. By default there is a one to one relationship on the number of rows OUT to the number of rows IN. You can choose to include columns from the input row in the output row by setting the column pass_through flag to TRUE. You can add new columns to the output resultset. Whether you have any passthrough columns or not, there is still a relationship between the number of input rows and the number of output rows the function will produce from your New_Columns tables. In other words you might set all of the input columns to pass_through=FALSE, but the PTF will only produce the number of rows from your New_Columns tables that match the number of rows of your input resultset.
There is a capability to specify how many output rows there are for any given input row using DBMS_TF.row_replication procedure (or a scalar parameter). The procedure version requires an argument that is an index-by table you populate with a numeric value for every input row in that fetch_rows call. Note how carefully I stated that. You can control the number of output rows counted for each and every input row by populating an array with a numeric value for every input row. You can do that for any of the fetch_rows calls but do not have to do so for all of them. If you do not call row_replication procedure during a particular fetch_rows, then you get one to one row output.
You can have 0, 1 or more output rows for any specific input row. If a column from an input row is marked with pass_through=TRUE, you will get that value in your output if replication factor is 1. You will get it on 2 rows if the replication factor is 2, etc… If the replication factor is 0 for that input row, you will not see that value in the output. In the diagram below, the input value from row 2 will not appear in the output resultset. The number of output rows will be the sum of the replication factor values.
| PTF Replication Factor |
|---|
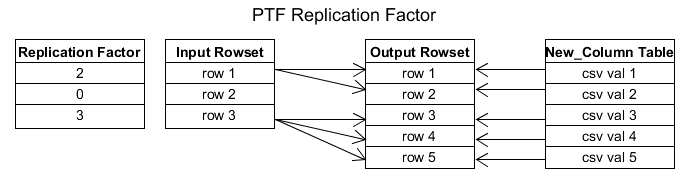 |
In the work I’ve done with CSV data I have been setting all input columns to pass_through=FALSE and using the replication_factor strictly as a way to tell Oracle how many output rows are in my output column arrays. When you have pass_through=TRUE you have to understand what Oracle does behind the scenes and how the two arrays match up.
Walk Through a PTF Example
We will walk through a Polymorphic Table Function and an associated package for creating a CSV file from an Oracle query. This requires Oracle 18c or better.
I have a prior effort for CSV file creation at app_csv_udt that should run under Oracle 10g or later. It is an Oracle Object Type, an approach I happen to like, but my coworkers not so much.
That earlier code is more complicated than this effort using a PTF. Oracle has taken care of most of the gnarly cursor management and bulk array processing leaving us with less to do in the PTF guts of our package. That doesn’t mean it is simple. I found the PTF functionality a struggle to grasp. The documentation is light and the examples I see published didn’t help me understand how it worked on the inside and what our design choices were as easily as I pick up many new things. When I look back at the examples different things stand out now than when I first went through them, so perhaps I just had a blind spot. I hope this article may help a few people learn about PTFs more easily.
The complete implementation can be found in the PLSQL_utilities library I maintain on github.
The PTF Components
- The PTF function specification may be standalone, but it makes sense to me to include it in the package. Since it is part of the package which has a descriptive name, I named the function simply ptf. Note that there is no function body for the PTF function and no entry for it in the package body. It exists only in the package specification.
- The describe function is a required element to support the PTF. It is usually not that complex (at least as far as I have seen so far).
- The fetch_rows procedure is where we do most of the work to transform our input resultset to an output resultset.
Here are the PTF components of the package specification for our Example. There are a few more utility procedures and functions we will add later. The package name is app_csv_pkg.
CREATE OR REPLACE PACKAGE app_csv_pkg
AUTHID CURRENT_USER
AS
--
-- All non numeric fields will be surrounded with double quotes. Any double quotes in the
-- data will be backwacked to protect them. Newlines in the data are passed through as is
-- which might cause issues for some CSV parsers.
FUNCTION ptf(
p_tab TABLE
,p_header_row VARCHAR2 := 'Y'
,p_separator VARCHAR2 := ','
-- you can set these to NULL if you want the default TO_CHAR conversions
,p_date_format VARCHAR2 := NULL
,p_interval_format VARCHAR2 := NULL
) RETURN TABLE PIPELINED
TABLE -- so can ORDER the input
--ROW
POLYMORPHIC USING app_csv_pkg
;
-- the describe and fetch methods are used exclusively by the PTF mechanism. You cannot
-- call them directly.
FUNCTION describe(
p_tab IN OUT DBMS_TF.TABLE_T
,p_header_row VARCHAR2 := 'Y'
,p_separator VARCHAR2 := ','
-- you can set these to NULL if you want the default TO_CHAR conversions
,p_date_format VARCHAR2 := NULL
,p_interval_format VARCHAR2 := NULL
) RETURN DBMS_TF.DESCRIBE_T
;
PROCEDURE fetch_rows(
p_header_row VARCHAR2 := 'Y'
,p_separator VARCHAR2 := ','
-- you can set these to NULL if you want the default TO_CHAR conversions
,p_date_format VARCHAR2 := NULL
,p_interval_format VARCHAR2 := NULL
)
;
...
Notice how the first argument to the function named ptf is of type TABLE. That is special in PTF land. It must be either a schema level table or view name, or else a Common Table Expression (CTE) (aka WITH clause). You cannot pass in a CURSOR or subselect. I vaguely understand the reasons for that, but not well enough to try to explain. The first argument with the same name is given to the describe function, but it has a different type.
If you have COLUMNS Pseudo-Operator arguments, they are to be the same between the PTF and describe functions (except for type – see below).
Neither the TABLE nor COLUMNS type arguments are passed to the fetch_rows procedure.
This gem from the DBMS_TF documentation says what I just said:
The arguments of the PTF function and DESCRIBE function must match, but with the type of any TABLE argument replaced with the DBMS_TF.TABLE_T descriptor type, and the type of any COLUMNS argument replaced with DBMS_TF.COLUMN_T descriptor.
All of the other arguments to all three methods are application specific and must be identical between the three methods. Even though you may not need the arguments in the describe function, the argument footprint much match what the SQL engine is going to provide in the call based on what it sees in the PTF definition.
It is interesting that our describe and fetch_rows methods are stateless. The SQL engine code that calls our methods maintains the state. When we call get/put methods that state is respected. There is an identifier called the XID that indexes that runtime state. It looks similar to the “Cursor id” value in DBMS_SQL.
The describe Function
From the package body:
FUNCTION describe(
p_tab IN OUT DBMS_TF.TABLE_T
,p_header_row VARCHAR2 := 'Y'
,p_separator VARCHAR2 := ','
-- you can set these to NULL if you want the default TO_CHAR conversions
,p_date_format VARCHAR2 := NULL
,p_interval_format VARCHAR2 := NULL
) RETURN DBMS_TF.DESCRIBE_T
AS
v_new_cols DBMS_TF.columns_new_t;
BEGIN
-- stop all input columns from being in the output
FOR i IN 1..p_tab.column.COUNT()
LOOP
p_tab.column(i).pass_through := FALSE;
p_tab.column(i).for_read := TRUE;
END LOOP;
-- create a single new output column for the CSV row string
v_new_cols(1) := DBMS_TF.column_metadata_t(
name => 'CSV_ROW'
,type => DBMS_TF.type_varchar2
);
-- we will use row replication to put a header out on the first row if desired
RETURN DBMS_TF.describe_t(new_columns => v_new_cols, row_replication => p_header_row IN ('Y','y'));
END describe
;
We need to examine all of the input column values but we do not want them to be passed through to our output rows. To that end we loop through the input column list setting pass_through to FALSE and for_read to TRUE.
We will be defining a single “new” column for our output rowset. To do that we need a table of column types which we get with the type DBMS_TF.columns_new_t for our variable v_new_cols. We then populate the first and only element of that table with a column_metadata_t record with values for the column name and column type. Note that the type is a numeric we get from a constant, not the descriptive name like ‘VARCHAR2’. Digesting this bit of convoluted crafting is where it is handy to be staring at the package specification for DBMS_TF. It is easier than hunting through the type definitions in the documentation.
The thing we return from the describe function is a describe_t record. We populate new_columns with the structure we populated for our new output column named ‘CSV_ROW’. We also provide a boolean value for row_replication. We set that to TRUE if we need to produce a header row. If we do not need to produce a header row, we will have one to one correspondence of output rows from input rows so no replication is required.
The fetch_rows Procedure
fetch_rows is where most of the work is done. There is a lot to unpack here
PROCEDURE fetch_rows(
p_header_row VARCHAR2 := 'Y'
,p_separator VARCHAR2 := ','
-- you can leave these NULL if you want the default TO_CHAR conversions for your session
,p_date_format VARCHAR2 := NULL
,p_interval_format VARCHAR2 := NULL
) AS
v_env DBMS_TF.env_t := DBMS_TF.get_env();
v_rowset DBMS_TF.row_set_t; -- the input rowset of CSV rows
v_row_cnt BINARY_INTEGER;
v_col_cnt BINARY_INTEGER;
--
v_val_col DBMS_TF.tab_varchar2_t;
v_repfac DBMS_TF.tab_naturaln_t;
v_fetch_pass BINARY_INTEGER := 0;
v_out_row_i BINARY_INTEGER := 0;
v_rowset will contain our input data for this fetch. v_val_col is a collection where we will place our output data for this fetch. v_repfac is where we MAY put a numeric value for each input row that will be 2 on the first row and 1 on all the rest. The reason we need that is to produce a header row. We need to output one more row than we have input rows, but we only need to do that on the first fetch. After that it won’t be necessary to populate or use v_repfac.
v_fetch_pass is used to determine whether or not we are on the first fetch and v_out_row_i is to keep track of the number of output rows on this fetch iteration.
-- If the user does not want to change the NLS formats for the session
-- but has custom coversions for this query, then we will apply them using TO_CHAR
TYPE t_conv_fmt IS RECORD(
t BINARY_INTEGER -- type
,f VARCHAR2(1024) -- to_char fmt string
);
TYPE t_tab_conv_fmt IS TABLE OF t_conv_fmt INDEX BY BINARY_INTEGER;
v_conv_fmts t_tab_conv_fmt;
--
FUNCTION apply_cust_conv(
p_col_index BINARY_INTEGER
,p_row_index BINARY_INTEGER
) RETURN VARCHAR2
IS
v_s VARCHAR2(4000);
BEGIN
v_s := CASE WHEN v_conv_fmts.EXISTS(p_col_index) THEN
'"'
||REPLACE(
CASE v_conv_fmts(p_col_index).t
WHEN DBMS_TF.type_date THEN
TO_CHAR(v_rowset(p_col_index).tab_date(p_row_index), v_conv_fmts(p_col_index).f)
WHEN DBMS_TF.type_interval_ym THEN
TO_CHAR(v_rowset(p_col_index).tab_interval_ym(p_row_index), v_conv_fmts(p_col_index).f)
WHEN DBMS_TF.type_interval_ds THEN
TO_CHAR(v_rowset(p_col_index).tab_interval_ds(p_row_index), v_conv_fmts(p_col_index).f)
END
, '"', '\\"'
) -- backwack the dquotes if any
||'"'
ELSE
DBMS_TF.col_to_char(v_rowset(p_col_index), p_row_index)
END;
IF SUBSTR(v_s,1,1) != '"' AND INSTR(v_s,p_separator) != 0 THEN
v_s := '"'||v_s||'"';
END IF;
RETURN v_s;
END; -- apply_cust_conv
BEGIN
The custom conversion code is a bit ugly. The default conversion to char provided by DBMS_TF.col_to_char() is almost perfect. It takes care of putting strings into double quotes and backwacking any embedded double quotes. For Date and Interval conversions it will also place the results in double quotes; however, for those it depends on the default string coversions (which can be further muddied by NLS_DATE_FORMAT).
The other oddity can happen when NLS_NUMERIC_CHARACTERS employs a comma. If we encounter a separator character in an unquoted value, we quote it.
Other than the use of DBMS_TF.col_to_char, this is standard PL/SQL (though perhaps a bit ugly), so I’m not going to expand on what it does other than to say it converts Oracle types to strings in a user specified manner while meeting the quoting needs for CSV output.
Now with the main fetch_rows body:
IF p_header_row IN ('Y','y') THEN
-- We need to put out a header row, so we have to engage in replication_factor shenanigans.
-- This is in case FETCH is called more than once. We get and put to the store
-- the fetch count.
-- get does not change value if not found in store so starts with our default 0 on first fetch call
DBMS_TF.xstore_get('v_fetch_pass', v_fetch_pass);
--dbms_output.put_line('xstore_get: '||v_fetch_pass);
ELSE
v_fetch_pass := 1; -- we do not need a header column. this will double as the flag
END IF;
If we need to produce a header row, then we need to know whether this is the first fetch call or not. We use xstore_get here and xstore_put later to maintain our state between calls to fetch_rows. If we do not need a header row, set our flag variable to skip that.
-- get the data for this fetch
DBMS_TF.get_row_set(v_rowset, v_row_cnt, v_col_cnt);
-- set up for custom TO_CHAR conversions if requested for date and/or interval types
FOR i IN 1..v_col_cnt
LOOP
IF (p_date_format IS NOT NULL AND v_env.get_columns(i).type = DBMS_TF.type_date)
THEN
v_conv_fmts(i) := t_conv_fmt(DBMS_TF.type_date, p_date_format);
ELSIF p_interval_format IS NOT NULL
AND v_env.get_columns(i).type IN (DBMS_TF.type_interval_ym, DBMS_TF.type_interval_ds)
THEN
v_conv_fmts(i) := t_conv_fmt(v_env.get_columns(i).type, p_interval_format);
END IF;
END LOOP;
We obtain the resultset data for this fetch, the number of rows and the number of columns. We then set up the custom conversion configuration if needed. Note that v_conv_fmts is sparse and possibly empty.
IF v_fetch_pass = 0 THEN -- this is first pass and we need header row
-- the first row of our output will get a header row plus the data row
v_repfac(1) := 2;
-- the rest of the rows will be 1 to 1 on the replication factor
FOR i IN 2..v_row_cnt
LOOP
v_repfac(i) := 1;
END LOOP;
-- these names are already double quoted and Oracle will not allow a doublequote inside a column alias
v_val_col(1) := v_env.get_columns(1).name;
FOR j IN 2..v_col_cnt
LOOP
v_val_col(1) := v_val_col(1)||p_separator||v_env.get_columns(j).name; --join the column names with ,
END LOOP;
v_out_row_i := 1;
--dbms_output.put_line('header row: '||v_val_col(1));
END IF;
-- otherwise v_out_row_i is 0
On the first fetch and only when we need to produce a header row, we set up our replication factor table. As stated above we want two output rows for the first input row, then one each for all the others.
We build the header row by joining the column names with the separator character (comma most likely).
Next we loop through the input rows building the corresponding output column (we only output a single column!).
FOR i IN 1..v_row_cnt
LOOP
v_out_row_i := v_out_row_i + 1;
-- concatenate the string representations of columns with ',' separator
-- into a single column for output on this row.
-- col_to_char() conveniently surrounds the character representation
-- of non-numeric fields with double quotes. If there is a double quote in
-- that data it will backwack it. Newlines in the field are passed through unchanged.
v_val_col(v_out_row_i) := apply_cust_conv(1, i); --DBMS_TF.col_to_char(v_rowset(1), i);
FOR j IN 2..v_col_cnt
LOOP
v_val_col(v_out_row_i) := v_val_col(v_out_row_i)||p_separator||apply_cust_conv(j, i); --DBMS_TF.col_to_char(v_rowset(j), i);
END LOOP;
END LOOP;
If we generated a header row on this pass we submit our replication_factor table, then store our state for the next fetch pass.
IF p_header_row IN ('Y','y') THEN -- save for possible next fetch call
IF v_fetch_pass = 0 THEN
-- only on the first fetch
DBMS_TF.row_replication(replication_factor => v_repfac);
END IF;
v_fetch_pass := v_fetch_pass + 1;
DBMS_TF.xstore_set('v_fetch_pass', v_fetch_pass);
END IF;
-- otherwies we did not do any replication and will get one for one with input rows
Notice that if we did not output a header row on this pass, we do not call DBMS_TF.row_replication.
And finally we tell the engine about our single output column collection.
DBMS_TF.put_col(1, v_val_col);
END fetch_rows;
Example Usage
An example including an ORDER BY clause for the PTF input:
WITH R AS (
SELECT last_name||', '||first_name AS "Employee Name", hire_date AS "Hire Date", employee_id AS "Employee ID"
FROM hr.employees
--ORDER BY last_name, first_name
) SELECT *
FROM app_csv_pkg.ptf(R ORDER BY ("Employee Name", "Hire Date")
, p_date_format => 'YYYYMMDD'
)
WHERE rownum <= 10
;
Output (notice how the header row counts as one of the 10 rows! It is just a data record in the resultset.):
"Employee Name","Hire Date","Employee ID"
"Abel, Ellen","20040511",174
"Ande, Sundar","20080324",166
"Atkinson, Mozhe","20051030",130
"Austin, David","20050625",105
"Baer, Hermann","20020607",204
"Baida, Shelli","20051224",116
"Banda, Amit","20080421",167
"Bates, Elizabeth","20070324",172
"Bell, Sarah","20040204",192
Conclusion
The package implementation at PLSQL_utilities library adds two get_clob functions and two write_file procedures that can be passed either a CURSOR (that is expected to end with a call to SELECT * FROM app_csv_pkg.ptf(…), or a SQL string CLOB that does the same.
This implementation has almost as much functionality as my original Object Oriented version that uses DBMS_SQL, but with a LOT less code. I think this version is also easier to understand once you get over the shock and awe around learning about Polymorphic Table Functions. I hope this article reduces the impact of that flash bang.