Introduction
In a prior post, Cost of UDT Object Methods in SQL, I hypothesized a performance issue was due to Context Switching between SQL and PL/SQL engine. Moving the suspect PL/SQL function call into a PIPELINED Table function solved the issue.
I had three outstanding doubts about what is really going on.
- The magnitude of the performance penalty caught me off gaurd. I’ve remediated context switch issues with function calls in a SQL SELECT list before. I haven’t seen one where the impact was this dramatic except where the PL/SQL function was also calling SQL.
- I am unsure whether Object type method calls in a SELECT list incur the context switch penalty. I still do not know and this analysis did not answer that question, but it did put the related subject of collection creation/extension cost into perspective.
- Unrelated, documentation for chained PIPELINED Table functions suggests bulk collect logic is not needed. I wanted to verify that.
PL/SQL Hierarchical Profiler
If you haven’t used the profiler before, this Jeff Smith post is a nice shortcut for getting started with SqlDeveloper taking care of some of the details. Remember to recompile with debug any of your packages and types that are called by the outer block if you want details for them. Once you get your feet wet, you can read the Oracle document Database Development Guide, Chapter 15, Using the PL/SQL Hierarchical Profiler.
Chained PIEPLINED Table Functions and Bulk Fetch
My working solution used chained PIPELINED Table functions. Per what I perceived the documetation to be implying (without ever coming out and saying it), I implemented the function that reads the cursor from the chain (not the first entry in the chain) without any bulk collection/array processing. The profiler showed that function taking 3.1% of the execution time.
Adding BULK COLLECT LIMIT 100 to the cursor fetch and processing the resulting array caused it to take 3.2% of the execution time (which could be noise) and there was no reduction in total run time. This appears to confirm that there is no advantage to buffering that cursor from one pipe row call to another. It is extra, unneeded processing.
Refactored Code to Analyze
The two variants we are comparing share most code. The one that does almost everything in the PL/SQL engine with a chained pipeline function is called like so:
v_sql := q'[INSERT /*+ APPEND WITH_PLSQL */ INTO ora$ptt_csv
WITH
a AS (
SELECT t.p AS pu
--perlish_util_udt(t.arr) AS pu
FROM TABLE(
app_csv_pkg.split_lines_to_fields(
CURSOR(SELECT *
FROM TABLE( app_csv_pkg.split_clob_to_lines(:p_clob, p_skip_lines => 1) )
)
, p_separator => :p_separator, p_strip_dquote => :p_strip_dquote, p_keep_nulls => 'Y'
)
) t
) SELECT ]'
-- must use table alias and fully qualify object name with it to be able to call function or get attribute of object
-- Thus alias x for a and use x.p.get vs a.p.get.
||v_cols.map('X.pu.get($##index_val##) AS "$_"').join('
,')
||'
FROM a X';
DBMS_OUTPUT.put_line(v_sql);
EXECUTE IMMEDIATE v_sql USING p_clob, p_separator, p_strip_dquote;
The one that does the perlish_util_udt constructor call (which calls app_csv_pkg.split_csv) from SQL is called like so:
v_sql := q'{INSERT /*+ APPEND WITH_PLSQL */ INTO ora$ptt_csv
WITH
a AS (
SELECT perlish_util_udt(
p_csv => t.s
,p_separator => :p_separator, p_strip_dquote => :p_strip_dquote, p_keep_nulls => 'Y'
,p_expected_cnt => :p_expected_cnt
) AS pu
FROM TABLE( app_csv_pkg.split_clob_to_lines(:p_clob, p_skip_lines => 1) ) t
) SELECT }'
-- must use table alias and fully qualify object name with it to be able to call function or get attribute of object
-- Thus alias x for a and use x.p.get vs a.p.get.
||v_cols.map('X.pu.get($##index_val##) AS "$_"').join('
,')
||'
FROM a X';
DBMS_OUTPUT.put_line(v_sql);
EXECUTE IMMEDIATE v_sql USING p_separator, p_strip_dquote, v_cols.arr.COUNT, p_clob ;
The perlish_util_udt constructor calls app_csv_pkg.csv. Both are called directly from PL/SQL in the first variant, but from SQL in the second. That is where we focus for this analysis.
Both were compiled with the following settings for the initial timed run:
ALTER SESSION SET plsql_code_type = NATIVE;
ALTER SESSION SET plsql_optimize_level=3;
Using a 10,766 row, 20 column CLOB input file the total run times are
| Variant | Run Time |
|---|---|
| PL/SQL | 9.0 |
| SQL | 94.9 |
If you read the prior article you will notice these times do not foot to those. There were multiple optimizations to the code since that article, most notably using REGEXP_INSTR to parse the CSV rows rather than REGEXP_SUBSTR. There is still a large percentage disparity between the two variants, though both are much faster now.
Running with Hierarchical Profile Enabled
The app_csv_pkg.split_csv procedure is modifed here to support additional data capture. You can see the original full package at https://github.com/lee-lindley/plsql_utilities.
PROCEDURE split_csv (
po_arr OUT NOCOPY &&d_arr_varchar2_udt.
,p_s CLOB
,p_separator VARCHAR2 DEFAULT ','
,p_keep_nulls VARCHAR2 DEFAULT 'N'
,p_strip_dquote VARCHAR2 DEFAULT 'Y' -- also unquotes \" and "" pairs within the field to just "
,p_expected_cnt NUMBER DEFAULT 0 -- will get an array with at least this many elements
)
-- when p_s IS NULL, returns initialized collection with COUNT=0
IS
v_str VARCHAR2(32767); -- individual parsed values cannot exceed 4000 chars
v_i BINARY_INTEGER := 0;
v_pos BINARY_INTEGER;
v_pos_last BINARY_INTEGER := 1;
v_last_had_separator BINARY_INTEGER := 0;
v_len BINARY_INTEGER;
v_regexp VARCHAR2(1024) := REPLACE(gc_csv_regexp, '__p_separator__', p_separator);
The local procedures defined next are to separate calls to built-in methods so that the profiler can capture the time spent on each separately.
-- these are to get profile info
PROCEDURE l_create_arr IS BEGIN po_arr := &&d_arr_varchar2_udt.(); END;
PROCEDURE l_extend_arr(p_cnt NUMBER) IS BEGIN po_arr.EXTEND(p_cnt); END;
PROCEDURE l_instr IS BEGIN v_pos := REGEXP_INSTR(p_s, v_regexp, v_pos_last, 1, 1); END;
PROCEDURE l_substr IS BEGIN v_str := TRIM(SUBSTR(p_s, v_pos_last, v_len)); END;
PROCEDURE l_repl_sep IS BEGIN v_str := REGEXP_REPLACE(v_str, '\\('||p_separator||')', '\1', 1, 0); END;
PROCEDURE l_strip_dq IS BEGIN
v_str := REGEXP_REPLACE(v_str,
'^"|"$' -- leading " or ending "
||'|["\\]' -- or one of chars " or \
||'(")' -- that is followed by a " and we capture that one in \1
,'\1' -- We put any '"' we captured back without the backwack or " quote
,1 -- start at position 1 in v_str
,0 -- 0 occurence means replace all of these we find
);
END;
BEGIN
--po_arr := &&d_arr_varchar2_udt.();
l_create_arr;
IF p_expected_cnt > 0 THEN
--po_arr.EXTEND(p_expected_cnt);
l_extend_arr(p_expected_cnt);
END IF;
IF p_s IS NOT NULL THEN
LOOP
--v_pos := REGEXP_INSTR(p_s, v_regexp, v_pos_last, 1, 1); -- get end char of matching string
l_instr;
-- the regexp WILL match until it matches the end of the string. Once v_pos_last
-- is on a character past the end of the string, it will return 0.
EXIT WHEN v_pos = 0;
v_last_had_separator := CASE WHEN SUBSTR(p_s, v_pos - 1, 1) = p_separator THEN 1 ELSE 0 END;
v_len := (v_pos - v_pos_last) - v_last_had_separator;
IF v_len > 0 THEN
--v_str := TRIM(SUBSTR(p_s, v_pos_last, v_len)); -- could still be null after trim
l_substr;
ELSE
v_str := NULL;
END IF;
IF v_str IS NOT NULL OR p_keep_nulls = 'Y' THEN
IF SUBSTR(v_str,1,1) = '"' THEN
IF p_strip_dquote = 'Y' THEN -- otherwise keep everything after trim which means should end on dquote
/*
v_str := REGEXP_REPLACE(v_str,
'^"|"$' -- leading " or ending "
||'|["\\]' -- or one of chars " or \
||'(")' -- that is followed by a " and we capture that one in \1
,'\1' -- We put any '"' we captured back without the backwack or " quote
,1 -- start at position 1 in v_str
,0 -- 0 occurence means replace all of these we find
);
*/
l_strip_dq;
END IF;
ELSIF v_str IS NOT NULL THEN
--v_str := REGEXP_REPLACE(v_str, '\\('||p_separator||')', '\1', 1, 0);
l_repl_sep;
END IF;
v_i := v_i + 1;
IF v_i > p_expected_cnt THEN -- otherwise we already have room
--po_arr.EXTEND;
l_extend_arr(1);
END IF;
po_arr(v_i) := v_str;
END IF;
v_pos_last := v_pos; -- walk the string to next token
END LOOP;
IF v_last_had_separator = 1 AND p_keep_nulls = 'Y' THEN -- trailing null
v_i := v_i + 1;
IF v_i > p_expected_cnt THEN -- otherwise we already have room
--po_arr.EXTEND;
l_extend_arr(1);
END IF;
po_arr(v_i) := NULL; -- do not think this is necessary, but make it explicit
END IF;
END IF; -- end if input string not null
END split_csv
;
Recompiling in DEBUG mode and with Profiling turned on, I expected some overhead to add to the run times and we do see that.
ALTER TYPE perlish_util_udt COMPILE DEBUG;
ALTER PACKAGE app_csv_pkg COMPILE DEBUG;
BEGIN
DBMS_HPROF.start_profiling('PLSHPROF_DIR', 'test.trc');
-- clob not listed for brevity
APP_CSV_PKG.create_ptt_csv(TO_CLOB(q'{...
...
}')
);
DBMS_HPROF.stop_profiling;
END;
/
SELECT COUNT(*)
FROM ora$ptt_csv
/
COMMIT
/
DECLARE
runid NUMBER;
BEGIN
runid := DBMS_HPROF.analyze(LOCATION => 'PLSHPROF_DIR', FILENAME => 'test.trc');
DBMS_OUTPUT.PUT_LINE('runid = ' || runid);
END;
/
The times are longer with profiling and debug mode, but still proportional.
| Variant | Run Time |
|---|---|
| PL/SQL | 13.0 |
| SQL | 141.7 |
Reading the Profiler Data
SqlDeveloper can show it to you including the HTML report it causes to be created in the database directory. That is convenient and I use it, but for this article I teased out the data I wanted to show.
with a as (
select function, namespace, sum(subtree_elapsed_time) as subtree_elapsed_time, sum(function_elapsed_time) as function_elapsed_time
from dbmshp_function_info
where runid = 5
group by function, namespace
), b as (
select function, namespace, sum(subtree_elapsed_time) as subtree_elapsed_time, sum(function_elapsed_time) as function_elapsed_time
from dbmshp_function_info
where runid = 6
group by function, namespace
) select NVL(b.function, a.function) as function
,NVL(b.namespace, a.namespace) as namespace
,TO_CHAR(a.subtree_elapsed_time/1000000, '999,999.9') AS called_from_sql_cum
,TO_CHAR(b.subtree_elapsed_time/1000000, '999,999.9') AS called_from_plql_cum
,TO_CHAR(a.function_elapsed_time/1000000, '999,999.9') AS called_from_sql_secs
,TO_CHAR(b.function_elapsed_time/1000000, '999,999.9') AS called_from_plsql_secs
from a
full outer join b
on (b.function = a.function --and b.line# = a.line#
)
OR (b.function = 'CREATE_PTT_CSV' AND a.function = 'CREATE_PTT_CSV_UDT')
order by NVL(a.subtree_elapsed_time, b.subtree_elapsed_time) desc
;
You may notice that the total times are a bit less than reported above. The difference I believe is that I’m reporting above the elapsed time in sqlplus, which includes the time to load the CLOB into memory.
| PL/SQL Hierarchical Profiler Data |
|---|
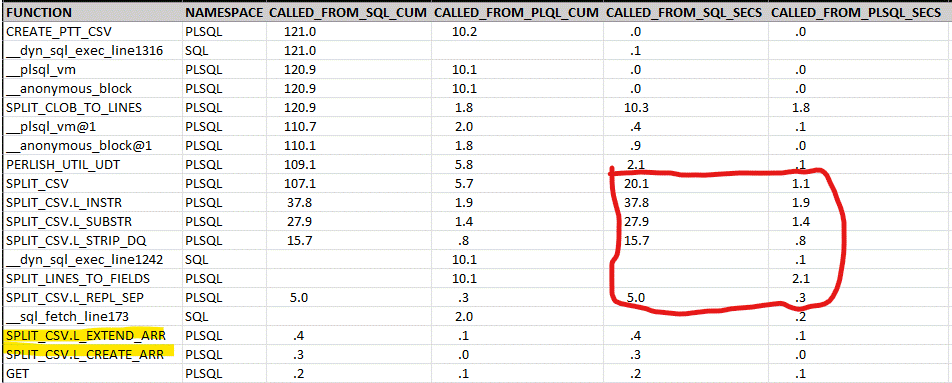 |
I find it interesting that two of the operations I was concerned with, creating the collection (SPLIT_CSV.L_CREATE_ARR) and extending/growing the collection (SPLIT_CSV.L_EXTEND_ARR), are non-factors.
My original premise was that context switching was the villain. If that were the entire story, I would expect the overall time for the function called from SQL to show the longer run time while the internal components of the call did not. In other words the impact of the context switch should only be at the beginning and end of the single call as we move memory around for the context switch. That is NOT what we see here.
Individual operations that should be taking place inside the PL/SQL engine for both runs have an elapsed time sum that is ten to twenty times longer when the function is called from SQL than when called from PL/SQL.
It is possible that I do not understand all implications of “context switching” here.
If the only discrepancies were in the regular expression engine, I would feel much better as that beast could be a weirdo. But we have anomalous behavior in the simple substring operation as well (SPLIT_CSV.L_SUBSTR) and that has nothing to do with the regular expression engine.
What the problem operations all have in common is reading and/or writing character data in memory. It may be that each of these operations incur the context switch penalty as they negotiate the “other” memory space.
I’m now at a point where I need to revisit my understanding of what context switch means for the SQL/PL_SQL interface. It isn’t like I haven’t been reading everything I could find on the subject for the last two weeks, yet somehow, exactly what goes on here has eluded me.
Stay tuned.